HW3 — DQN 及其變體
以 Deep Reinforcement Learning in Action 第三章 Gridworld 為底,三階段實作並比較 DQN 的演進。
GitHub 原始碼 ·
PyTorch 2.5 + Lightning 2.6 · Windows / CPU 全程可重現
HW3-1 · Naive DQN + Experience Replay static 模式
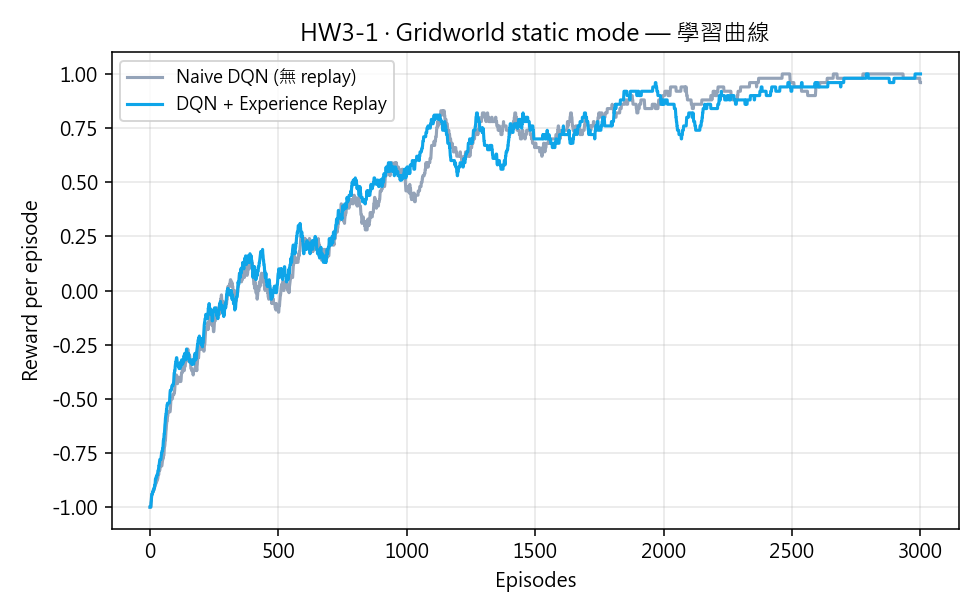 有 / 無 Experience Replay 的回合獎勵比較(100 回合移動平均)。
有 / 無 Experience Replay 的回合獎勵比較(100 回合移動平均)。
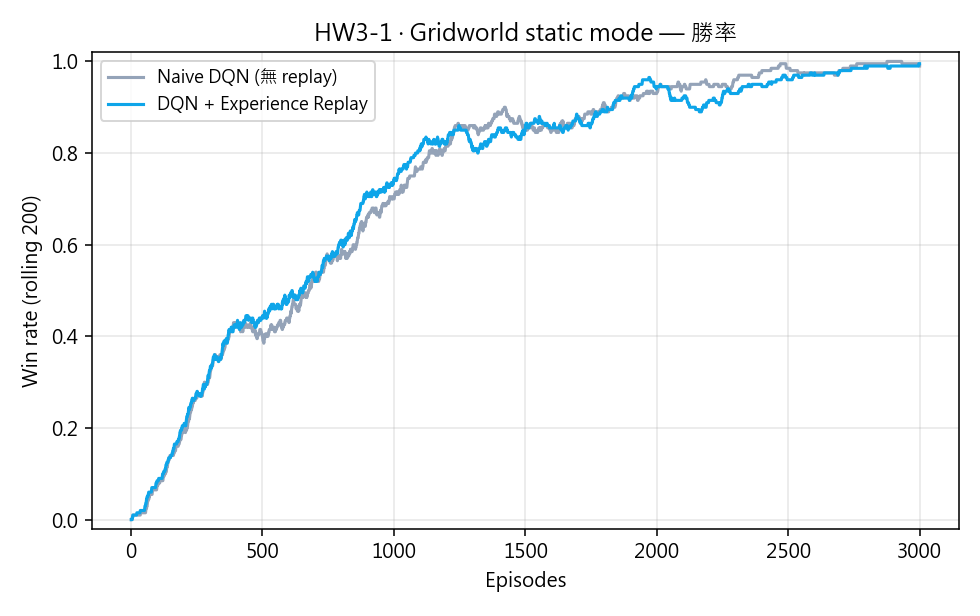 最後 200 回合勝率 ≈ 99%。
最後 200 回合勝率 ≈ 99%。
 訓練完成的 Q-network 從起點走到 goal(7 步)。
訓練完成的 Q-network 從起點走到 goal(7 步)。
HW3-2 · Double DQN 與 Dueling DQN player 模式 player 模式
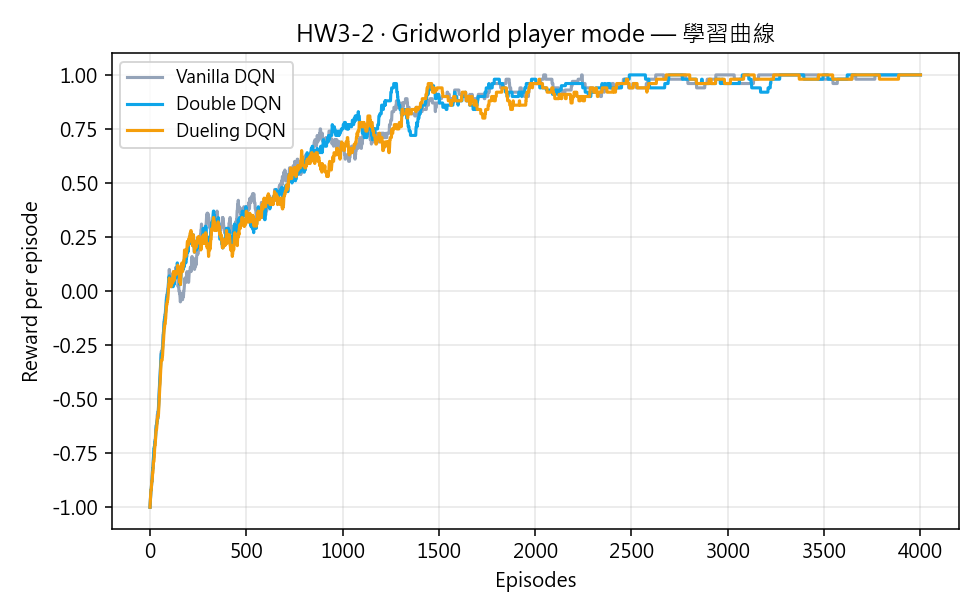 Vanilla / Double / Dueling DQN 的每回合獎勵。
Vanilla / Double / Dueling DQN 的每回合獎勵。
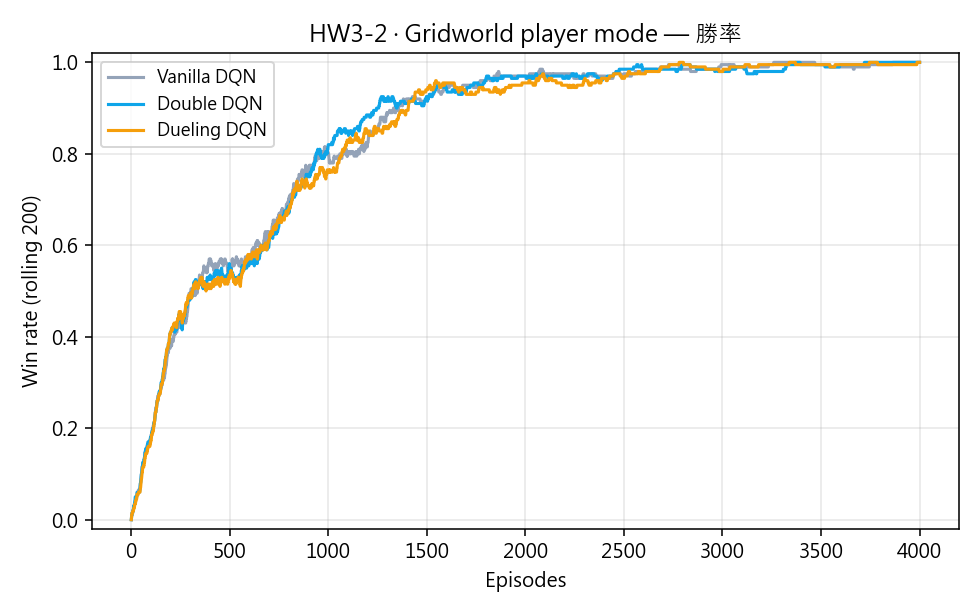 三者最終皆收斂至勝率 1.00。
三者最終皆收斂至勝率 1.00。
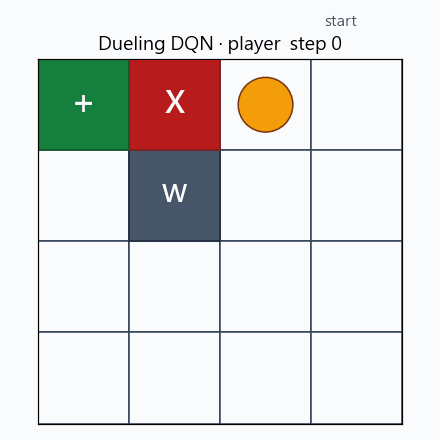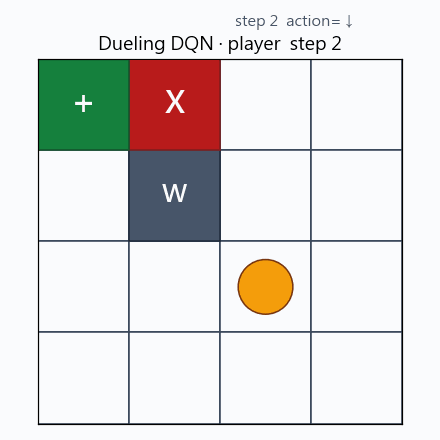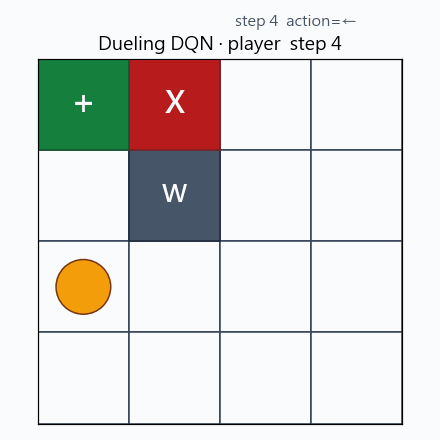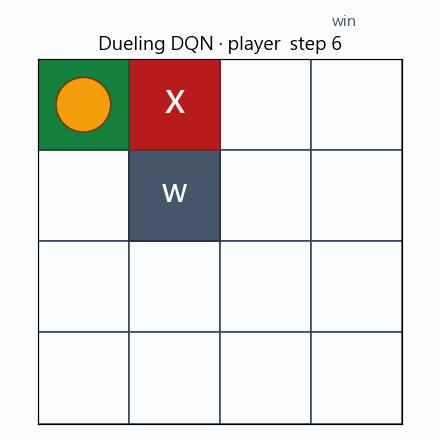 Dueling DQN 於 player 模式下的一回合 greedy rollout。
Dueling DQN 於 player 模式下的一回合 greedy rollout。
| 改進 | 重點 |
|---|
| Double DQN |
online 網路挑動作、target 網路估值 ⇒ 緩解 max-operator 帶來的過度估計偏差。 |
| Dueling DQN |
拆成 V(s) + A(s, a) 兩個分支 ⇒ 即使各動作 Q 值差很小,也能正確學到「這個狀態本身多好」。 |
HW3-3 · PyTorch Lightning + Training Tips random 模式
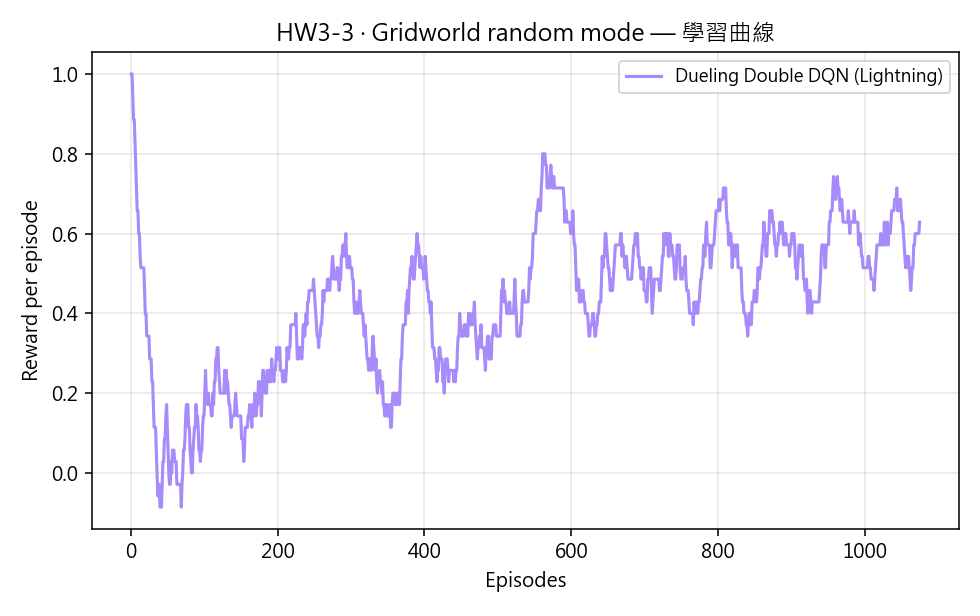 Dueling Double DQN + 穩定性技巧的學習曲線。
Dueling Double DQN + 穩定性技巧的學習曲線。
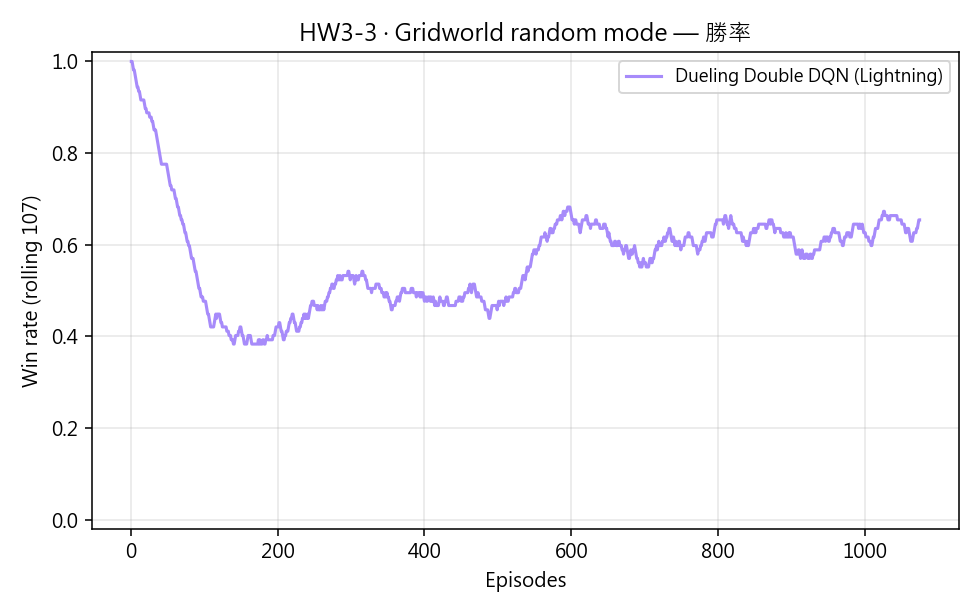 最後 300 回合勝率 ≥ 60%(random mode 上限本身較低)。
最後 300 回合勝率 ≥ 60%(random mode 上限本身較低)。
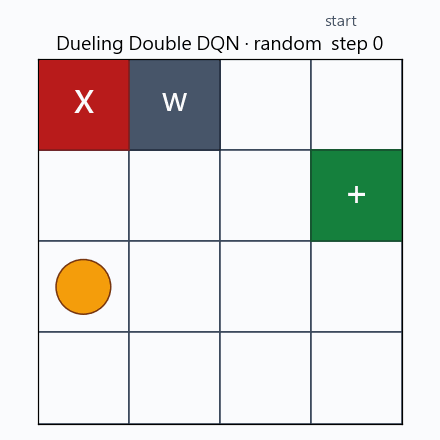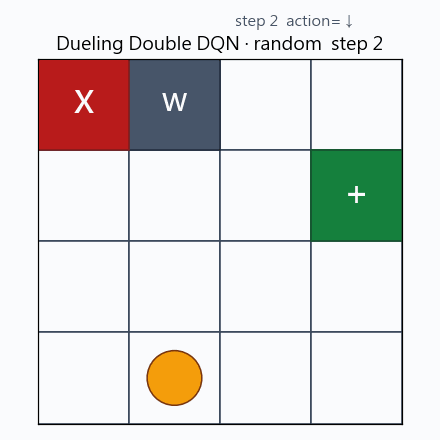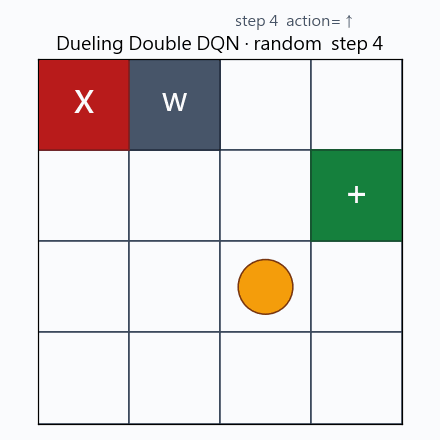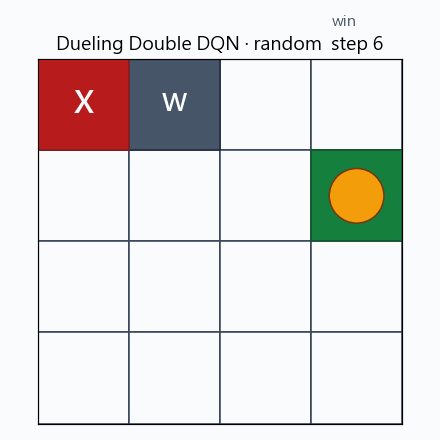 隨機關卡下的 greedy rollout。
隨機關卡下的 greedy rollout。
加入的訓練技巧
| 技巧 | 設定 | 為什麼有用 |
|---|
| 梯度裁剪 | gradient_clip_val = 1.0 | 避免 Q-learning 早期目標震盪造成的梯度爆炸 |
| Cosine LR annealing | 1e-3 → 1e-5 | 末期細調 Q 值,避免 overshoot |
| Target soft update | τ = 0.005(每步) | 比 hard sync 更平滑,顯著減少訓練中途崩潰 |
| ε 指數衰減 | 0.05 + 0.95·exp(−3·t/5000) | 前期快探索、中期迅速收斂、後期仍保留少量探索 |
| Warm-up buffer | 500 步才開始更新 | 避免過早以偏誤樣本更新網路 |
結論
- Experience Replay 對 static 的 4×4 Gridworld 影響不大(環境本身太簡單),但會在 player / random mode 顯著加速收斂。
- player mode 下 Vanilla / Double / Dueling DQN 收斂後差異不大(上限 = 100%),差別在中段穩定性;換到 random mode 才能明顯看出 Dueling 與 Double 的優勢。
- Lightning 本身不會讓 agent 學得更好,但封裝後的 trainer-level 設定(梯度裁剪、LR schedule、soft update)一次掛上去就明顯穩定 random mode 的訓練。